Engineering
Cutting down on AI model usage costs by 40% with monitoring and evaluation
Friday, April 18, 2025
No items found.
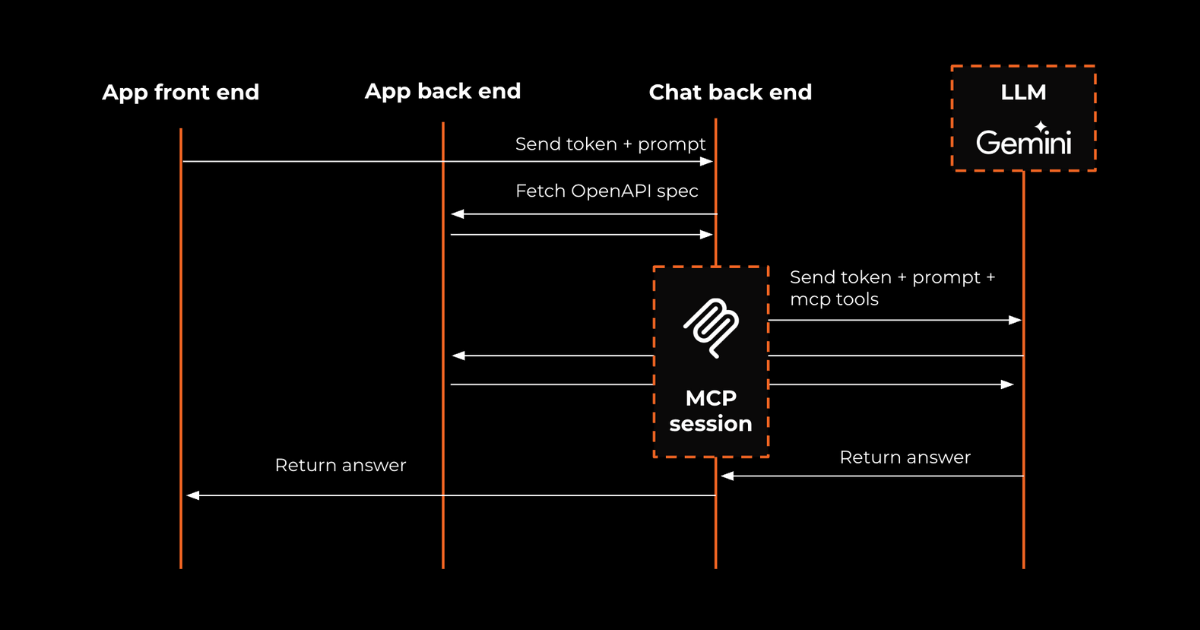
For one of our clients we recently built an agentic workflow with 10+ distinct chained LLM calls. After the initial build, the latency of the agent was large and the output accuracy insufficient.
We solved this problem by implementing diligent monitoring and evaluation metrics for each step in the workflow, using Helicone (YC W23) as a useful tool in this process. In doing so, we gradually discovered hidden insights to adapt our LLM flow, radically improve output accuracy and cut down model usage costs by over 40%! We're always happy to share learnings about our approach.

×
![Modal Image]()
See also
.png)
.png)
Let's build. Together!
We’ll be happy to hear more about your latest product development initiatives. Let’s discover how we can help!
Oops! Something went wrong while submitting the form.
Are you looking for an entrepreneurial product development partner? Never hesitate to schedule a virtual coffee.
Egwin Avau
Founder & CEO
Schedule a call

Koen Verschooten
Operations manager
Schedule a call